Kafka Streams, the Clojure way
In this blog post, I’ll walk you through how to create a Kafka Streams application in an idiomatic Clojure style. I won’t assume any knowledge of Kafka or Kafka Streams, but if you’ve never heard of them before this post may be a bit overwhelming - I’d check out Confluent’s introduction to Kafka Streams , and also the Kafka Streams docs .
Kafka can be thought of as a persistent, highly scalable, distributed message queue. Kafka stores all messages in “topics”, which can be produced to and consumed from. Kafka Streams is an abstraction on top of Kafka, which treats topics as a reactive stream of data onto which you can apply transformations (map, filter, etc.). It also gives you a way to perform stateful aggregations, in such a way that your application can be safely restarted.
The Java API for Kafka Streams is very powerful, but has a few drawbacks. It gives you a mutable StreamsBuilder
object, on which you call methods like .map(...) and .filter(...). You use this builder object to build a Topology
, a logical representation of your application as a graph of processing nodes. You then use the Topology to initialise a KafkaStreams
object, which executes the topology’s logic. We’ll develop an application in this style using the Jackdaw
library, a Clojure library for Kafka, and then evolve it into a more idiomatic, data-driven style. All the code I’m going to show you is in this walkthrough repo
, so clone it now if you’d like to follow along.
A Simple Example
Let’s imagine that you work at Fidget-no-more Incorporated, the world’s largest purveyor of fidget spinners (or whatever the kids are buying nowadays). Your website currently records every purchase in a DB, but other departments are finding it difficult to write applications that react when a purchase is made. The sales team would like their apps to somehow be notified when a large purchase is made, so they can send the user a personalised thank you email. This sounds like the perfect job for Kafka! Here’s what we’ll do:
- On every purchase, produce a message to the
purchase-madeKafka topic. - Create a Kafka Streams app that:
- Reads from this topic
- Filters for large purchases (above £100)
- Removes any extraneous fields from each message (the sales team only need a user id and an amount)
- Writes to the
large-transaction-madetopic
Before we start, we need to start up a Kafka “broker”, a server running Kafka. The easiest way to do this is to spin up a landoop/fast-data-dev Docker container. You can do this by running the following command (you’ll need Docker installed):
# On Linux
docker run --rm --net=host landoop/fast-data-dev
# On Mac
docker run --rm -p 2181:2181 -p 3030:3030 -p 8081-8083:8081-8083 -p 9581-9585:9581-9585 -p 9092:9092 -e ADV_HOST=localhost landoop/fast-data-dev:latest
We’ll start by creating the purchase-made and large-transaction-made topics. Clone the walkthrough repo
if you haven’t already, and start up your repl. Navigate to the kafka-streams-the-clojure-way.core namespace, and run these commands:
;; create the "purchase-made" and "large-transaction-made" topics
(ja/create-topics! admin-client [purchase-made-topic large-transaction-made-topic])
By the way - all the commands we’re going to run are in the comment block at the bottom of the kafka-streams-the-clojure-way.core namespace.
We now need to produce some dummy messages onto the purchase-made topic. These messages are going to look like this:
{:id 1
:user-id 1234
:amount 20
:quantity 5}
We’ve already got a make-purchase! function defined for us in the kafka-streams-the-clojure-way.core namespace, so just run these commands:
;; Make a few dummy purchases
(make-purchase! 10)
(make-purchase! 500)
(make-purchase! 50)
(make-purchase! 1000)
If you’re interested in how make-purchase! works, check out the code in the walkthrough repo. It uses the Kafka (not Kafka Streams) API, so I’ll just gloss over it here.
You should see in the fast-data-dev UI that messages appear in the topic. Now we have a topic with some dummy data in it, we can start writing our Kafka Streams topology. This is already defined in the walkthrough repo, here’s the code:
(defn simple-topology [builder]
(-> ;; Read the purchase-made topic into a KStream
(js/kstream builder purchase-made-topic)
;; Filter the KStream for purchases greater than £100
(js/filter (fn [[_ purchase]]
(<= 100 (:amount purchase))))
;; Remove all but the :amount and :user-id fields from the message.
;; Note that the function passed to map takes and returns a tuple of [key value].
(js/map (fn [[key purchase]]
[key (select-keys purchase [:amount :user-id])]))
;; Write our KStream to the large-transaction-made topic
(js/to large-transaction-made-topic)))
(defn start! []
"Starts the simple topology"
(let [builder (js/streams-builder)]
(simple-topology builder)
(doto (js/kafka-streams builder kafka-config)
(js/start))))
(defn stop! [kafka-streams-app]
"Stops the given KafkaStreams application"
(js/close kafka-streams-app))
Run (def app (start!)) in the repl to start the topology. You should shortly see messages appear on the large-transaction-made topic. Magic! Try producing some more messages to the purchase-made topic, and your topology should pick them up and process them immediately. When you’re ready to move on, run (stop! app) to stop the topology.
Introducing Transducers
We’ve made a good start, but there are a few problems with our code at the moment. One is that our code is not as easy to test as it could be. We can’t directly test the logic of our topology, because it’s tied to the Kafka Streams API. You can use Kafka’s TopologyTestDriver to run your topology in memory, but this can be quite cumbersome. It would be much easier if we could express our topology’s logic as pure functions, and then test them. Secondly, our code isn’t very composable. If you have 2 separate topologies, there is no easy way of merging them together. Thirdly, the code is tied to a specific context - Kafka Streams. If you want to re-use the same logic for transforming, for example, a core.async channel you’d be forced to re-write it.
To alleviate these problems, we’re going to use transducers . Transducers are “a powerful and composable way to build algorithmic transformations that you can reuse in many contexts”. Basically, they allow you to encapsulate the logic of transforming a stream of data, without specific knowledge of what the stream is. The stream could be a seq, a core.async channel, or a Kafka topic. If you’re not familiar with them already, you may want to check out this introductory blog post . Let’s write a transducer that captures the logic of our topology:
(def purchase-made-transducer
(comp
;; Note that each step takes a [key value] tuple
(filter (fn [[_ purchase]]
(<= 100 (:amount purchase))))
(map (fn [[key purchase]]
[key (select-keys purchase [:amount :user-id])]))))
We can easily test the transducer in the repl like this:
(into []
purchase-made-transducer
[[1 {:purchase-id 1 :user-id 2 :amount 10 :quantity 1}]
[3 {:purchase-id 3 :user-id 4 :amount 500 :quantity 100}]])
We’ve successfully isolated the logic of our topology as a pure function. This enables us to easily test our topology’s logic. Now we’ll update our topology to use this transducer. We’re going to use the transduce-stream function here - you don’t need to know exactly how it works, only that it applies a transducer to a KStream.
(defn build-topology-with-transducer [builder]
(-> (js/kstream builder purchase-made-topic)
(transduce-stream purchase-made-transducer)
(js/to large-transaction-made-topic)))
Great, this seems to have made our code more testable, flexible, and composable.
A more complicated Example
Unfortunately, your boss now comes to you with another requirement (as they always do). Your company has just launched a new way of buying fidget spinners - The Humble Spinner Bundle™. Your customers pay whatever they think is fair for a bundle of 10 (ten!) fidget spinners. This is on a completely separate site, but luckily the team in charge of building it have created a Kafka topic for you, onto which they’ll publish all the purchases of the humble bundle - humble-donation-made. The sales team would like to send a congratulatory email to customers who pay a large amount for the bundle, in the same way as they do for regular purchases. Therefore, you’ve been tasked with consuming this topic in your application. Unfortunately, the team building the humble-donation-made topic have come up with a message schema that’s slightly different to purchase-made. humble-donation-made messages look like this:
{:user-id 1234
:donation-amount-cents 1000 ;; £10
:donation-date "2019-01-02"}
We’ll need to create a KStream from the humble-donation-made topic, apply a transducer to it, then use Jackdaw’s merge function to merge it with the KStream from our previous topology. Let’s start with the transducer for the humble-donation-made topic:
(def humble-donation-made-transducer
(comp
;; Again, each step takes a [key value] tuple
(filter (fn [[_ donation]]
(<= 10000 (:donation-amount-cents donation))))
(map (fn [[key donation]]
[key {:user-id (:user-id donation)
:amount (int (/ (:donation-amount-cents donation) 100))}]))))
Now for the topology itself, this is what the code looks like:
(defn more-complicated-topology [builder]
(js/merge
(-> (js/kstream builder purchase-made-topic)
(transduce-stream purchase-made-transducer))
(-> (js/kstream builder humble-donation-made-topic)
(transduce-stream humble-donation-made-transducer))))
This will work, but we’ve re-introduced all the problems we had before we started using transducers. Our code is now less testable, less composable, and less portable. As Clojure programmers, we know exactly what to do when we’re confronted with this problem - express everything as data! If only there were a library that could help us out…
Introducing Willa
Willa
is just such a library. It allows you to express your topology as data and functions, rather than using the mutable StreamsBuilder API. Full disclosure - I’m the author of Willa, so if you’re looking for an unbiased critique of it, I’d just stop reading now. Let’s see how it would affect our code. We’ll start by defining all our topics and KStreams. In Willa, these are called “entities”. We first need to construct a map of entity id to entity config, like so:
(def entities
;; We'll define our topic entities first
;; For the values, we just need to add the ::w/entity-type to our existing topic configs
{:topic/purchase-made (assoc purchase-made-topic ::w/entity-type :topic)
:topic/humble-donation-made (assoc humble-donation-made-topic ::w/entity-type :topic)
:topic/large-transaction-made (assoc large-transaction-made-topic ::w/entity-type :topic)
;; We now define our KStreams
;; This is where we define the transducers we apply to the KStream, as the ::w/xform key
:stream/large-purchase-made {::w/entity-type :kstream
::w/xform purchase-made-transducer}
:stream/large-donation-made {::w/entity-type :kstream
::w/xform humble-donation-made-transducer}})
So far so good. We now need to define how our topics and streams relate to each other - how the data flows through our topology. Willa models a topology as a graph (a DAG) of entities. You express this as a vector of tuples. Each tuple has 2 elements, in the format [:entity-id-from :entity-id-to], and represents a directed edge on the topology graph. Willa calls this a “workflow”. Our workflow looks like this:
(def workflow
[[:topic/purchase-made :stream/large-purchase-made]
[:topic/humble-donation-made :stream/large-donation-made]
;; When there are multiple edges pointing to the same node, Willa will merge the inputs by default
[:stream/large-purchase-made :topic/large-transaction-made]
[:stream/large-donation-made :topic/large-transaction-made]])
Putting it together:
(def topology
{:workflow workflow
:entities entities})
That’s all we need to do to completely specify our topology. One nice advantage of doing it this way is that we can now visualise our topology. Run this command in the repl:
(wv/view-topology topology)
You should see a diagram like this:
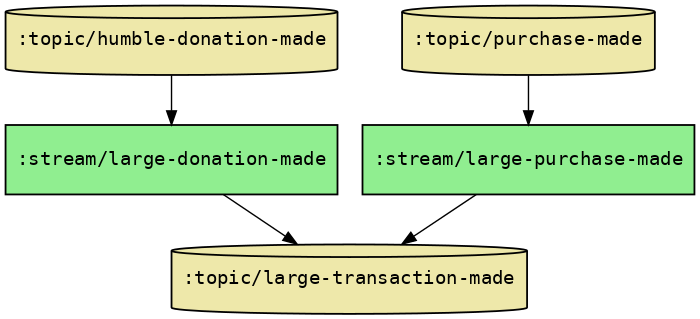
Nice! To get it running, we just need a few lines of code to compile Willa’s representation of our topology into an actual Kafka Streams topology:
;; Create the humble-purchase-made topic
(ja/create-topics! admin-client [humble-donation-made-topic])
;; Start the topology
(let [builder (js/streams-builder)]
(w/build-topology! builder topology)
(js/start (js/kafka-streams builder kafka-config)))
;; Publish a couple of messages to the input topics
(make-purchase! 200)
(make-humble-donation! 15000)
You should now see some more messages appear in the large-transaction-made topic .
So now we’ve completely specified our topology as data structures and transducers. What does that give us, other than being able to brag to other developers about how decomplected our code is? (Note - please don’t do that). One advantage is that, as we saw earlier, we’re able to test each transducer in isolation without knowing anything about Kafka Streams. We can also see how data flows through our topology, without interacting with Kafka at all. Willa calls this an “experiment”. Run this in the repl:
;; Run an experiment
(def experiment
(we/run-experiment
topology
{:topic/purchase-made [{:key 1
:value {:id 1
:amount 200
:user-id 1234
:quantity 100}}]
:topic/humble-donation-made [{:key 2
:value {:user-id 2345
:donation-amount-cents 15000
:donation-date "2019-01-02"}}]}))
;; Visualise experiment result
(wv/view-topology experiment)
;; View results as data
(we/results-only experiment)
The experiment results should look like this:
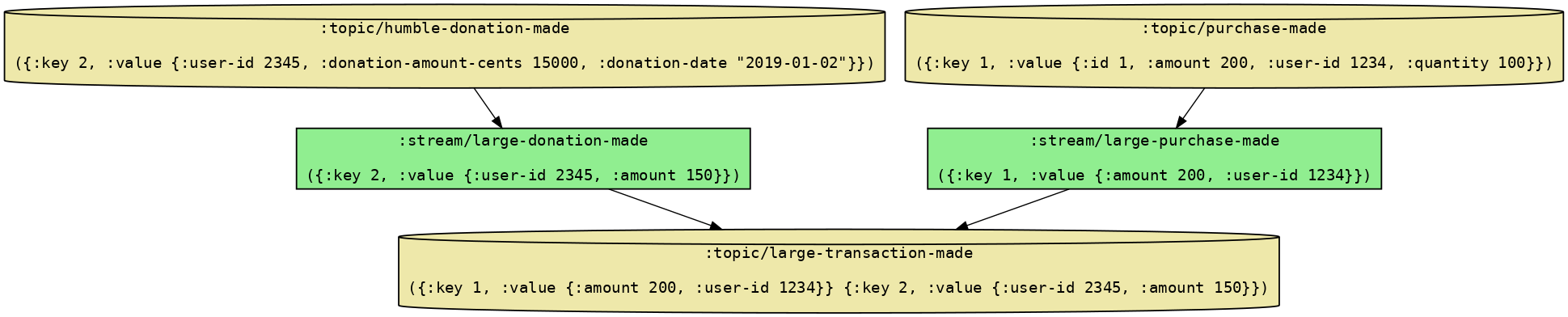
You can also verify that the topology is valid in the repl, using clojure.spec . You can do this by running:
;; Should print "Success!!"
(s/explain ::ws/topology topology)
;; What happens with an invalid topology?
(s/explain ::ws/topology
;; introduce a loop in our topology, which is not allowed
(update topology :workflow conj [:topic/large-transaction-made :topic/purchase-made]))
The real advantage of Willa is that it relies on standard Clojure data structures as much as possible. This allows you to do things like serialise your topology as EDN, programatically manipulate it, and also query it - for example, try writing a function to count the number of topics involved in a topology.
Summary
I hope that’s given you a brief overview of how to write a basic Kafka Streams topology. If you’re interested in learning more I’d recommend reading Kafka 101
and Designing Event Driven Systems
. I’d also recommend this Kafka Streams Udemy course
. We’ve barely scratched the surface of Kafka Streams, there are many more concepts to learn (😓). We haven’t even touched on things like KTables, aggregations, or joins. Willa is just an experiment at this point, but hopefully it’s given you some food for thought. I’d also recommend checking out the ksml
and Noah
libraries, which have similar goals to Willa but a slightly different approach. Thanks for reading, please don’t hesitate to email me if you have any questions or comments.